[1] 배경
AWS 환경의 리소스에 대한 자세한 데이터를 보유하는 것은 여러 가지 이유로 중요해졌습니다.. 요청에 따라 보고, 청구, 구성 추적, 보안 평가 또는 감사 목적으로 사용될 수 있도록 문서화가 필요했기 때문입니다. AWS 환경 개요를 원하는 IT 관리자, 클라우드 관리자 또는 기타 이해관계자에게 매우 유용하게 쓰일 수 있어야 합니다. 본질적으로 특정 AWS 리소스의 스냅샷을 Excel 파일로 가져오고 통합하고 표시하는 도구를 만들기 위해 스크립트를 활용하면 생산성을 증대시킬 수 있습니다. 가져온 데이터를 Excel 파일에 저장하면 데이터를 보고, 공유하고, 분석할 수 있는 구조화된 방법을 제공합니다. 형식을 지정하면 데이터의 가독성과 유용성이 향상됩니다.
[2] 작업 내용
아래의 작성된 스크립트를 통해 AWS(Amazon 웹 서비스)와 인터페이스하여 특정 리소스에 대한 세부 정보를 가져온 다음 가져온 데이터를 openpyxl 라이브러리를 사용하여 Excel 파일에 저장하는 Python 스크립트를 만듭니다.
리소스 출력
AWS Resources Overview:
- 스크립트는
boto3Python용 AWS SDK인 라이브러리를 사용하여 AWS 서비스와 상호 작용하고 데이터를 가져옵니다. - EC2 인스턴스, RDS 인스턴스, VPCs, 서브넷
NAT Gateway :
describe_nat_gateways코드는 의 함수를 사용하여ec2_clientNAT 게이트웨이 목록을 검색합니다.- 각 NAT 게이트웨이에 대해 NAT 게이트웨이 이름, ID, 연결된 IP 주소, VPC ID 및 서브넷 ID와 같은 관련 정보를 추출합니다.
- 이 데이터는 Excel 통합 문서에 새로 생성된 ‘NAT 게이트웨이’ 시트에 저장됩니다.
Route Tables :
- 코드는
route_tables.all()함수를 사용하여 모든 경로 테이블을 검색합니다. - 각 경로에 대해 경로 테이블 이름, ID, 대상 CIDR 블록, 게이트웨이 ID 및 연결된 서브넷 ID와 같은 세부 정보를 추출합니다.
- 이 데이터는 Excel 통합 문서의 새로운 ‘라우팅 테이블'(라우팅 테이블) 시트에 저장됩니다.
- 일부 코드는 값이 동일한 경우 Excel 시트의 셀을 병합하는 데 사용됩니다.
보안 그룹(SG) :
describe_security_groups코드는 의 함수를 사용하여ec2_client보안 그룹 목록을 검색합니다.- 그런 다음 각 보안 그룹의 인바운드 및 아웃바운드 규칙에 대한 정보를 추출합니다.
- 관련 IP 정보와 함께 규칙이 목록에 추가됩니다.
- 이 정보는 인스턴스의 데이터와 결합되어 Excel 통합 문서의 새로운 ‘보안 그룹'(보안 그룹) 시트에 저장됩니다.
EBS(탄력적 블록 스토어) :
- 스크립트는 환경의 모든 EBS 볼륨에 대한 세부 정보를 가져오기 위해
describe_volumes호출 합니다.ec2_client - 각 볼륨의 인스턴스 이름, 볼륨 이름, 크기 및 총 크기와 같은 관련 정보를 추출합니다.
- 이 데이터는 Excel 통합 문서의 새로운 ‘EBS’ 시트에 저장됩니다.
기능 동작
Excel 작업: 스크립트는 openpyxl라이브러리를 사용하여 Excel 작업을 처리합니다.
- Excel 통합 문서 생성 : 새로운 통합 문서가 생성되고, AWS 리소스에 대한 데이터가 다른 시트에 기록됩니다.
- Excel 시트 형식 지정 : 스크립트는 Excel 시트의 헤더 형식을 지정하고, 데이터의 테두리를 설정하고, 열 너비를 조정하고, 스크롤할 때 계속 표시되도록 헤더 행을 고정합니다.
추가 유틸리티 기능:
make_instance_list: 이 기능은 실행되지 않는 EC2 인스턴스를 필터링하고 인스턴스를 보안 그룹과 매핑합니다.make_rds_instance_list: 이 기능은 RDS 인스턴스를 보안 그룹 ID와 매핑합니다.set_border: 엑셀 시트에서 특정 범위에 대한 테두리를 설정하는 유틸리티 함수입니다.
가정 및 제한:
- 사용자 데이터 : 스크립트에는
userAWS에 대한 액세스 키, 비밀 키 및 지역이 포함된 하드코딩된 목록이 있으며 이는 안전하지 않을 수 있습니다. 일반적으로 이 데이터를 안전한 방식(예: AWS Secrets Manager)으로 저장하거나 역할을 사용합니다. - 출력 Excel 파일 이름 : 출력 파일의 이름은 계정 닉네임과 현재 날짜를 사용하여 구성됩니다.
- 인스턴스 액세스 데이터 : 스크립트에는
server_id, , 등과 같은 특정 데이터에 대한 자리server_pw표시 자가 있습니다os. 이를 가져오려면 추가 논리가 필요하거나 나중에 수동으로 입력해야 할 수 있습니다.
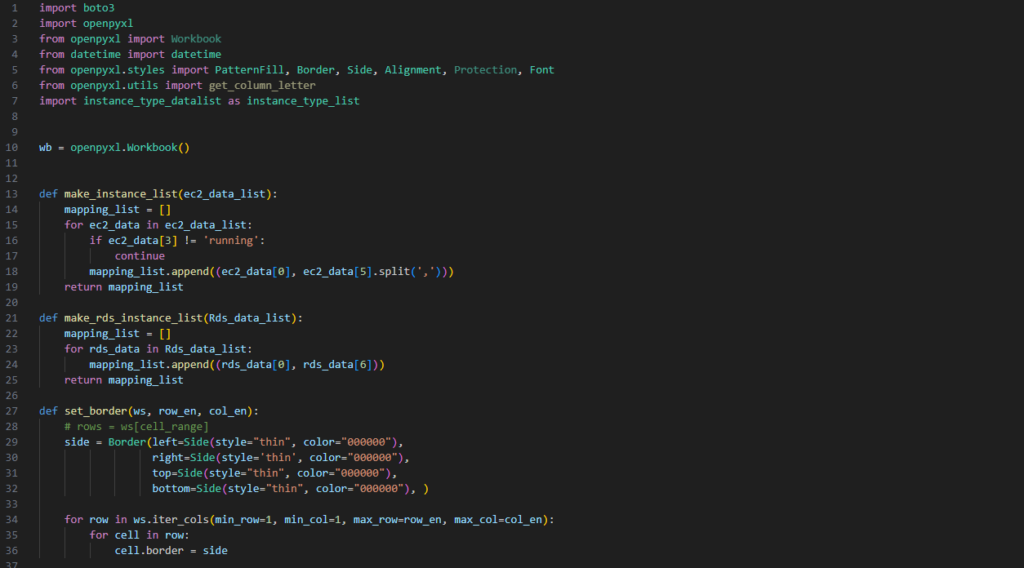
소스파일 > servelistr.py
import boto3
import openpyxl
from openpyxl import Workbook
from datetime import datetime
from openpyxl.styles import PatternFill, Border, Side, Alignment, Protection, Font
from openpyxl.utils import get_column_letter
import instance_type_datalist as instance_type_list
wb = openpyxl.Workbook()
def make_instance_list(ec2_data_list):
mapping_list = []
for ec2_data in ec2_data_list:
if ec2_data[3] != 'running':
continue
mapping_list.append((ec2_data[0], ec2_data[5].split(',')))
return mapping_list
def make_rds_instance_list(Rds_data_list):
mapping_list = []
for rds_data in Rds_data_list:
mapping_list.append((rds_data[0], rds_data[6]))
return mapping_list
def set_border(ws, row_en, col_en):
# rows = ws[cell_range]
side = Border(left=Side(style="thin", color="000000"),
right=Side(style='thin', color="000000"),
top=Side(style="thin", color="000000"),
bottom=Side(style="thin", color="000000"), )
for row in ws.iter_cols(min_row=1, min_col=1, max_row=row_en, max_col=col_en):
for cell in row:
cell.border = side
user = ['AccountNick', 'AccountDescription', 'AccessKey', 'SecretAccessKey', 'RegionId']
access_key = user[2]
secret_key = user[3]
region = user[4]
excelName = user[0] + '_Server_List_' + datetime.now().strftime("%Y%m%d") + '_v0.1.xlsx'
####EC2
ec2_client = boto3.client('ec2', aws_access_key_id=access_key, aws_secret_access_key=secret_key,
region_name=region)
desc_instances = ec2_client.describe_instances()
print(desc_instances)
ec2_data_list = []
for reservation in desc_instances.get('Reservations'):
for instance in reservation.get('Instances'):
instance_name = None
for tags in instance.get('Tags')if instance.get('Tags') else '':
if tags.get('Key') == 'Name':
instance_name = tags.get('Value')
instance_id = instance.get('InstanceId')
instance_type = instance.get('InstanceType')
instance_state = instance.get('State').get('Name')
instance_az = instance.get('Placement').get('AvailabilityZone')
instance_sg = ''
for sg in instance.get('NetworkInterfaces'):
for network in sg.get('Groups'):
instance_sg += network.get('GroupName') + ','
instance_sg = instance_sg[:-1]
private_ip = instance.get('PrivateIpAddress')
public_ip = instance.get('PublicIpAddress')
data_tuple = (
instance_name,
instance_id,
instance_type,
instance_state,
instance_az,
instance_sg,
private_ip,
public_ip
)
ec2_data_list.append(data_tuple)
sheet1 = wb.active
sheet1.title = '서버리스트'
header = (
'InstanceName', 'InstanceId', 'InstanceType',
'State', 'AvailabilityZone', 'SecurityGroup',
'PrivateIpAddress', 'PublicIpAddress'
)
sheet1.append(header)
i = 0
for data_row in ec2_data_list:
print(data_row)
++i
sheet1.append(data_row)
header_list = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']
for header_style in header_list:
sheet1[header_style + '1'].font = Font(name='Calibri', size=11, bold=True,color='FFFFFF')
sheet1[header_style + '1'].fill = PatternFill(fill_type="solid", start_color='366092', end_color='366092')
sheet1[header_style + '1'].alignment = Alignment(horizontal='center', vertical='center')
set_border(sheet1, i, 8)
sheet1.column_dimensions['A'].width = 30
sheet1.column_dimensions['B'].width = 21
sheet1.column_dimensions['C'].width = 14
sheet1.column_dimensions['D'].width = 8
sheet1.column_dimensions['E'].width = 16
sheet1.column_dimensions['F'].width = 100
sheet1.column_dimensions['G'].width = 17
sheet1.column_dimensions['H'].width = 17
sheet1.freeze_panes = 'A2'
####RDS
RDS_client = boto3.client('rds', aws_access_key_id=access_key, aws_secret_access_key=secret_key,
region_name=region)
rds = RDS_client.describe_db_instances()
Rds_data_list =[]
for ridata in rds.get('DBInstances'):
DBInstanceIdentifier = ridata.get('DBInstanceIdentifier')
Engine = ridata.get('Engine')
EngineVersion = ridata.get('EngineVersion')
InstanceCreateTime = ridata.get('InstanceCreateTime')
LatestRestorableTime = ridata.get('LatestRestorableTime')
DBInstanceClass = ridata.get('DBInstanceClass')
for data in ridata.get('VpcSecurityGroups'):
VpcSecurityGroupId = data.get('VpcSecurityGroupId')
data_tuple = (
DBInstanceIdentifier,
Engine,
EngineVersion,
InstanceCreateTime,
LatestRestorableTime,
DBInstanceClass,
VpcSecurityGroupId
)
Rds_data_list.append(data_tuple)
sheet_rds = wb.create_sheet('RDS')
header = (
'DBInstanceIdentifier','Engine', 'EngineVersion', 'InstanceCreateTime',
'LatestRestorableTime', 'DBInstanceClass','SecurityGroupId'
)
sheet_rds.append(header)
for data_row in Rds_data_list:
print(data_row)
sheet_rds.append(data_row)
header_list = ['A', 'B', 'C', 'D', 'E','F''G']
for header_style in header_list:
sheet_rds[header_style + '1'].font = Font(name='Calibri', size=11, bold=True,color='FFFFFF')
sheet_rds[header_style + '1'].fill = PatternFill(fill_type="solid", start_color='366092', end_color='366092')
sheet_rds[header_style + '1'].alignment = Alignment(horizontal='center', vertical='center')
set_border(sheet_rds, i, 7)
sheet_rds.column_dimensions['A'].width = 20
sheet_rds.column_dimensions['B'].width = 21
sheet_rds.column_dimensions['C'].width = 30
sheet_rds.column_dimensions['D'].width = 30
sheet_rds.column_dimensions['E'].width = 30
sheet_rds.column_dimensions['F'].width = 20
sheet_rds.column_dimensions['G'].width = 20
sheet_rds.freeze_panes = 'A2'
###Access
ebs = ec2_client.describe_volumes()
cpu_mem_list = instance_type_list.instance_list
Access_data_list = []
for reservation in desc_instances.get('Reservations'):
for instance in reservation.get('Instances'):
instance_name = None
for tags in instance.get('Tags'):
if tags.get('Key') == 'Name':
instance_name = tags.get('Value')
ebs_total_size = 0
instance_id = instance.get('InstanceId')
for instance_ebs in ebs.get('Volumes'):
for instance_det in instance_ebs.get('Attachments'):
ebs_id = instance_det.get('InstanceId')
ebs_this_size = instance_ebs.get('Size')
if instance_id == ebs_id:
ebs_total_size += ebs_this_size
instance_description = ''
instance_hostname = ''
private_ip = instance.get('PrivateIpAddress')
public_ip = instance.get('PublicIpAddress')
instance_state = instance.get('State').get('Name')
instance_type = instance.get('InstanceType')
instance_az = instance.get('Placement').get('AvailabilityZone')
key_name = instance.get('KeyName')
port = ''
server_id = ''
server_pw = ''
os = ''
os_type = ''
cpu = ''
memory = ''
for match in cpu_mem_list:
if instance_type == match[0]:
cpu = match[1]
memory = match[2]
disk = ebs_total_size
data_tuple = (
instance_name,
instance_az,
instance_description,
instance_hostname,
instance_state,
instance_type,
cpu,
memory,
disk,
os,
os_type,
key_name,
private_ip,
public_ip,
port,
server_id,
server_pw
)
Access_data_list.append(data_tuple)
sheet5 = wb.create_sheet('Access')
sheet5['A1'] = 'EC2 인스턴스 접속 정보'
sheet5['A1'].font = Font(name='Calibri', size=15, bold=True)
header = (
'InstanceName', 'Location', 'Description', 'Hostname', 'state', 'Instance Type', 'vCPU', 'Memory', 'Disk', 'OS',
'OS Type', 'Key Name',
'PrivateIpAddress', 'PublicIpAddress', 'Port', 'ID', 'PW'
)
i = 0
sheet5.append(header)
for data_row in Access_data_list:
print(data_row)
++i
sheet5.append(data_row)
header_list = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q']
for header_style in header_list:
sheet5[header_style + '2'].font = Font(name='Calibri', size=11, bold=True, color='FFFFFF')
sheet5[header_style + '2'].fill = PatternFill(fill_type="solid", start_color='366092', end_color='366092')
set_border(sheet5, i, 17)
sheet5.column_dimensions['A'].width = 32
sheet5.column_dimensions['B'].width = 20
sheet5.column_dimensions['C'].width = 20
sheet5.column_dimensions['D'].width = 17
sheet5.column_dimensions['E'].width = 17
sheet5.column_dimensions['F'].width = 17
sheet5.column_dimensions['G'].width = 5
sheet5.column_dimensions['H'].width = 5
sheet5.column_dimensions['I'].width = 10
sheet5.column_dimensions['J'].width = 17
sheet5.column_dimensions['K'].width = 17
sheet5.column_dimensions['L'].width = 17
sheet5.column_dimensions['M'].width = 17
sheet5.column_dimensions['N'].width = 17
sheet5.column_dimensions['O'].width = 17
sheet5.column_dimensions['P'].width = 17
sheet5.column_dimensions['Q'].width = 17
############# VPC
desc_vpcs = ec2_client.describe_vpcs()
print(desc_vpcs)
data_list = []
for vpc in desc_vpcs.get('Vpcs'):
cidr_block = vpc.get('CidrBlock')
if '172.31' in cidr_block:
print()
else:
vpc_name = None
vpc_id = vpc.get('VpcId')
cidr_block = vpc.get('CidrBlock')
vpc_tags = vpc.get('Tags')
if vpc_tags:
for tag in vpc_tags:
if tag.get('Key') == 'Name':
vpc_name = tag.get('Value')
data_tuple = (
vpc_name if vpc_name else "",
vpc_id,
cidr_block
)
data_list.append(data_tuple)
data_list.sort(key=lambda data: data[0])
sheet3 = wb.create_sheet('VPC')
header = ('VPC Name', 'Vpc Id', 'Cidr Block')
sheet3.append(header)
i = 0
for data_row in data_list:
#print(data_row)
++i
sheet3.append(data_row)
header_list = ['A', 'B', 'C']
for header_style in header_list:
sheet3[header_style + '1'].font = Font(name='Calibri', size=11, bold=True,color='FFFFFF')
sheet3[header_style + '1'].fill = PatternFill(fill_type="solid", start_color='366092', end_color='366092')
sheet3[header_style + '1'].alignment = Alignment(horizontal='center', vertical='center')
set_border(sheet3, i, 3)
sheet3.column_dimensions['A'].width = 32
sheet3.column_dimensions['B'].width = 32
sheet3.column_dimensions['C'].width = 20
sheet3.freeze_panes = 'A2'
############## subnet
desc_subnet = ec2_client.describe_subnets()
#print(desc_subnet)
subnet_data_list = []
for subnet in desc_subnet.get('Subnets'):
cidr_block = subnet.get('CidrBlock')
if '172.31' in cidr_block:
print()
else:
subnet_name = None
cidr_block = subnet.get('CidrBlock')
subnet_az = subnet.get('AvailabilityZone')
subnet_id = subnet.get('SubnetId')
vpc_id = subnet.get('VpcId')
subnet_tags = subnet.get('Tags')
if subnet_tags:
for tag in subnet_tags:
if tag.get('Key') == 'Name':
subnet_name = tag.get('Value')
data_tuple = (
subnet_name if subnet_name else "",
cidr_block,
subnet_az,
subnet_id,
vpc_id
)
subnet_data_list.append(data_tuple)
subnet_data_list.sort(key=lambda data: data[0])
sheet7 = wb.create_sheet('서브넷')
header = ('Subnet Name','Cidr Block','Availability Zone', 'Subnet Id', 'Vpc Id')
sheet7.append(header)
i = 0
for data_row2 in subnet_data_list:
#print(data_row2)
++i
sheet7.append(data_row2)
header_list = ['A', 'B', 'C', 'D', 'E']
for header_style in header_list:
sheet7[header_style + '1'].font = Font(name='Calibri', size=11, bold=True,color='FFFFFF')
sheet7[header_style + '1'].fill = PatternFill(fill_type="solid", start_color='366092', end_color='366092')
sheet7[header_style + '1'].alignment = Alignment(horizontal='center', vertical='center')
set_border(sheet7, i, 5)
sheet7.column_dimensions['A'].width = 32
sheet7.column_dimensions['B'].width = 20
sheet7.column_dimensions['C'].width = 20
sheet7.column_dimensions['D'].width = 32
sheet7.column_dimensions['E'].width = 32
sheet7.freeze_panes = 'A2'
####### Nat Gateway
desc_nat_gateway = ec2_client.describe_nat_gateways()
#print(desc_nat_gateway)
nat_gateway_data_list = []
for nat_gateway in desc_nat_gateway.get('NatGateways'):
nat_gateway_name = None
nat_gateway_id = nat_gateway.get('NatGatewayId')
private_ip = nat_gateway.get('NatGatewayAddresses')[0]['PrivateIp']
public_ip = nat_gateway.get('NatGatewayAddresses')[0]['PublicIp']
vpc_id = nat_gateway.get('VpcId')
subnet_id = nat_gateway.get('SubnetId')
nat_gateway_tags = nat_gateway.get('Tags')
if nat_gateway_tags:
for tag in nat_gateway_tags:
if tag.get('Key') == 'Name':
nat_gateway_name = tag.get('Value')
data_tuple = (
nat_gateway_name,
nat_gateway_id,
public_ip,
private_ip,
vpc_id,
subnet_id
)
nat_gateway_data_list.append(data_tuple)
sheet8 = wb.create_sheet('NAT Gateway')
header = ('Name','ID', 'Public IP', 'Private IP','VPC ID','Subnet ID')
sheet8.append(header)
i = 0
for data_row2 in nat_gateway_data_list:
#print(data_row2)
++i
sheet8.append(data_row2)
header_list = ['A', 'B', 'C', 'D', 'E', 'F']
for header_style in header_list:
sheet8[header_style + '1'].font = Font(name='Calibri', size=11, bold=True,color='FFFFFF')
sheet8[header_style + '1'].fill = PatternFill(fill_type="solid", start_color='366092', end_color='366092')
sheet8[header_style + '1'].alignment = Alignment(horizontal='center', vertical='center')
set_border(sheet8, i, 6)
sheet8.column_dimensions['A'].width = 32
sheet8.column_dimensions['B'].width = 32
sheet8.column_dimensions['C'].width = 17
sheet8.column_dimensions['D'].width = 17
sheet8.column_dimensions['E'].width = 30
sheet8.column_dimensions['F'].width = 30
sheet8.freeze_panes = 'A2'
########## Route Table
ec2_resource = boto3.resource('ec2', aws_access_key_id=access_key, aws_secret_access_key=secret_key, region_name=region)
desc_rtb = ec2_resource.route_tables.all()
#print(desc_rtb)
data_list = []
for route_table in desc_rtb:
route_table_name = None
route_table_id = None
destination_cidr_block = None
gateway_id = None
subnet_id = None
for ra in route_table.routes_attribute:
# if ra.get('DestinationCidrBlock') == '0.0.0.0/0' and ra.get('GatewayId') is None:
destination_cidr_block = ra.get('DestinationCidrBlock')
if destination_cidr_block is None:
continue
else:
route_table_id = route_table.id
for tag in route_table.tags:
if tag.get('Key') == 'Name':
route_table_name = tag.get('Value')
gateway_id = ra.get('GatewayId')
for rsa in route_table.associations_attribute:
subnet_id = rsa.get('SubnetId')
data_tuple = (
route_table_name if route_table_name else "",
route_table_id,
destination_cidr_block,
gateway_id,
subnet_id
)
data_list.append(data_tuple)
data_list.sort(key=lambda data: data[0])
sheet4 = wb.create_sheet('라우팅테이블')
header = ('RouteTableName', 'RouteTableId', 'DestinationCidrBlock', 'GatewayId', 'SubnetId')
sheet4.append(header)
i = 0
for data_row in data_list:
#print(data_row)
++i
sheet4.append(data_row)
for now_col in range(65,67):
count_cell = sheet4.max_row +1
print(count_cell)
cells = sheet4[chr(now_col)+'2:'+chr(now_col)+str(count_cell)]
merge_init = 2
merge_end = 2
for merge in cells:
cell = merge[0]
# print(f'{cell.value}')
pre_cell = sheet4.cell(row= merge_end-1, column=now_col-64)
# print(pre_cell.value)
if cell.value == pre_cell.value:
merge_end +=1
else:
sheet4.merge_cells(start_row=merge_init -1, end_row=merge_end-1, start_column=now_col - 64, end_column=now_col - 64)
merge_init = merge_end + 1
merge_end +=1
for alig in range(2,count_cell):
sheet4[chr(now_col)+str(alig)].alignment = Alignment(horizontal='center', vertical='center')
header_list = ['A', 'B', 'C', 'D', 'E']
for header_style in header_list:
sheet4[header_style + '1'].font = Font(name='Calibri', size=11, bold=True,color='FFFFFF')
sheet4[header_style + '1'].fill = PatternFill(fill_type="solid", start_color='366092', end_color='366092')
sheet4[header_style + '1'].alignment = Alignment(horizontal='center', vertical='center')
set_border(sheet4, i, 5)
sheet4.column_dimensions['A'].width = 32
sheet4.column_dimensions['B'].width = 32
sheet4.column_dimensions['C'].width = 17
sheet4.column_dimensions['D'].width = 35
sheet4.column_dimensions['E'].width = 35
sheet4.freeze_panes = 'A2'
############ SG
desc_sgs = ec2_client.describe_security_groups()
#print(desc_sgs)
instance_list = make_instance_list(ec2_data_list)
rds_instance_list = make_rds_instance_list(Rds_data_list)
sg_data_dict = dict()
sg_data_list = []
for sg in desc_sgs.get('SecurityGroups'):
group_name = sg.get('GroupName')
GroupId = sg.get('GroupId')
for perm in sg.get('IpPermissions'):
from_port = str(perm.get('FromPort'))
to_port = str(perm.get('ToPort'))
if from_port == 'None' or from_port == '-1':
port_range = 'ALL'
elif from_port == to_port:
port_range = from_port
else:
port_range = from_port + ' - ' + to_port
ip_protocol = str(perm.get('IpProtocol'))
if ip_protocol == 'None' or ip_protocol == '-1':
ip_protocol = 'ALL'
for ip in perm.get('IpRanges'):
ip_cidr = ip.get('CidrIp')
ip_desc = ip.get('Description')
in_out_bound = '인바운드'
data_tuple = (
group_name,
in_out_bound,
port_range,
ip_protocol,
ip_cidr,
ip_desc,
GroupId
)
if group_name in sg_data_dict:
sg_data_dict[group_name].append(data_tuple)
else:
sg_data_dict[group_name] = [data_tuple]
if GroupId in sg_data_dict:
sg_data_dict[GroupId].append(data_tuple)
else:
sg_data_dict[GroupId] = [data_tuple]
for perm in sg.get('IpPermissionsEgress'):
from_port = str(perm.get('FromPort'))
to_port = str(perm.get('ToPort'))
if from_port == 'None' or from_port == '-1':
port_range = 'ALL'
elif from_port == to_port:
port_range = from_port
else:
port_range = from_port + ' - ' + to_port
ip_protocol = str(perm.get('IpProtocol'))
if ip_protocol == 'None' or ip_protocol == '-1':
ip_protocol = 'ALL'
for ip in perm.get('IpRanges'):
ip_cidr = ip.get('CidrIp')
ip_desc = ip.get('Description')
in_out_bound = '아웃바운드'
data_tuple = (
group_name,
in_out_bound,
port_range,
ip_protocol,
ip_cidr,
ip_desc,
GroupId
)
if group_name in sg_data_dict:
sg_data_dict[group_name].append(data_tuple)
else:
sg_data_dict[group_name] = [data_tuple]
if GroupId in sg_data_dict:
sg_data_dict[GroupId].append(data_tuple)
else:
sg_data_dict[GroupId] = [data_tuple]
sg_data_list = []
for instance_data in instance_list:
for group_name in instance_data[1]:
#if group_name == 'OT_nat_security':
# continue
for sg_data in sg_data_dict[group_name]:
sg_append_data = [instance_data[0]] + list(sg_data)
sg_data_list.append(tuple(sg_append_data))
print(sg_append_data)
for instance_data in rds_instance_list:
print(instance_data)
# if instance_data[1] == sg_data_dict[GroupId]:
GroupId = instance_data[1]
for sg_data in sg_data_dict[GroupId]:
sg_append_data = [instance_data[0]] + list(sg_data)
sg_data_list.append(tuple(sg_append_data))
print(sg_append_data)
sheet2 = wb.create_sheet('보안그룹')
header = ('InstanceName', 'GroupName', 'in/out bound', 'PortRange', 'IpProtocol', 'CidrIp', 'Description')
sheet2.append(header)
i =0
for data_row in sg_data_list:
#print(data_row)
++i
sheet2.append(data_row)
for now_col in range(65,68):
count_cell = sheet2.max_row + 1
print(count_cell)
cells = sheet2[chr(now_col)+'2:'+chr(now_col)+str(count_cell)]
merge_init = 2
merge_end = 2
# cells2 = sheet2['A1': 'B3']
# for c1, c2 in cells2:
# print("{0:8} {1:8}".format(c1.value, c2.value))
# print(type(cells))
# print(cells)
for merge in cells:
cell = merge[0]
# print(f'{cell.value}')
pre_cell = sheet2.cell(row= merge_end-1, column=now_col-64)
# print(pre_cell.value)
if cell.value == pre_cell.value:
merge_end +=1
else:
sheet2.merge_cells(start_row=merge_init -1, end_row=merge_end-1, start_column=now_col - 64, end_column=now_col - 64)
merge_init = merge_end + 1
merge_end +=1
for alig in range(2,count_cell):
sheet2[chr(now_col)+str(alig)].alignment = Alignment(horizontal='center', vertical='center')
header_list = ['A', 'B', 'C', 'D', 'E', 'F', 'G']
for header_style in header_list:
sheet2[header_style + '1'].font = Font(name='Calibri', size=11, bold=True,color='FFFFFF')
sheet2[header_style + '1'].fill = PatternFill(fill_type="solid", start_color='366092', end_color='366092')
sheet2[header_style + '1'].alignment = Alignment(horizontal='center', vertical='center')
set_border(sheet2, i, 7)
sheet2.column_dimensions['A'].width = 32
sheet2.column_dimensions['B'].width = 32
sheet2.column_dimensions['C'].width = 20
sheet2.column_dimensions['D'].width = 20
sheet2.column_dimensions['E'].width = 20
sheet2.column_dimensions['F'].width = 20
sheet2.column_dimensions['G'].width = 30
sheet2.freeze_panes = 'A2'
sheet2.delete_cols(8)
############# EBS
ebs = ec2_client.describe_volumes()
ebs_data_list = []
instance_name_list = []
idx = 1
for instance in ebs.get('Volumes'):
for instance_det in instance.get('Attachments'):
ebs_id = instance_det.get('InstanceId')
ebs_total_size = ''
for ec2_name in ec2_data_list:
if ebs_id == ec2_name[1]:
ebs_id = ec2_name[0]
ebs_size = instance.get('Size')
volume_name = None
for tags in instance.get('Tags')if instance.get('Tags') else '':
if tags.get('Key') == 'Name':
volume_name = tags.get('Value')
iops = instance.get('Iops')
data_tuple = (
ebs_id if ebs_id else '',
volume_name,
ebs_size,
ebs_total_size
)
ebs_data_list.append(data_tuple)
ebs_data_list.sort(key=lambda data: data[0])
sheet6 = wb.create_sheet('EBS')
header = (
'Instance Name', 'Volume Name', 'Size', 'Total Size'
)
tot_size = 0
ac_list = list()
for data in ebs_data_list:
a = data[0]
c = data[2]
ac_tuple = (
a,
c
)
ac_list.append(ac_tuple)
print(ac_list)
sheet6.append(header)
for data_row in ebs_data_list:
data_row_list = list(data_row)
# print(a_list)
for A_data in ac_list:
if data_row[0] == A_data[0]:
each_size = A_data[1]
# print(A_data)
tot_size += each_size
data_row_list[3] =tot_size
# print(tot_size)
tot_size=0
data_row_tp = tuple(data_row_list)
sheet6.append(data_row_tp)
# print(data_row)
count_cell = sheet6.max_row +1
print(count_cell)
cells = sheet6['A2:A'+str(count_cell)]
merge_init = 2
merge_end = 2
for merge in cells:
cell = merge[0]
pre_cell = sheet6.cell(row= merge_end-1, column=1)
if cell.value == pre_cell.value:
merge_end +=1
else:
sheet6.merge_cells(start_row=merge_init -1, end_row=merge_end-1, start_column=1, end_column=1)
sheet6.merge_cells(start_row=merge_init - 1, end_row=merge_end - 1, start_column=4, end_column=4)
merge_init = merge_end + 1
merge_end +=1
for alig in range(2,count_cell):
sheet6['A'+str(alig)].alignment = Alignment(horizontal='center', vertical='center')
sheet6['D' + str(alig)].alignment = Alignment(horizontal='center', vertical='center')
header_list = ['A', 'B', 'C', 'D']
for header_style in header_list:
sheet6[header_style + '1'].font = Font(name='Calibri', size=11, bold=True,color='FFFFFF')
sheet6[header_style + '1'].fill = PatternFill(fill_type="solid", start_color='366092', end_color='366092')
sheet6[header_style + '1'].alignment = Alignment(horizontal='center', vertical='center')
set_border(sheet6, i, 4)
sheet6.column_dimensions['A'].width = 32
sheet6.column_dimensions['B'].width = 32
sheet6.column_dimensions['C'].width = 15
sheet6.column_dimensions['D'].width = 15
sheet6.freeze_panes = 'A2'
#wb.save(excelName)
wb.save(excelName)
wb.close()
소스파일 > instance_type_datalist.py
instance_list = [
["r5.large", 2, 16],
["r5.xlarge", 4, 32],
["r5.2xlarge", 8, 64],
["r5.4xlarge", 16, 128],
["r5.8xlarge", 32, 256],
["r5.12xlarge", 48, 384],
["r5.16xlarge", 64, 512],
["r5.24xlarge", 96, 768],
["r4.large", 2, 15.25],
["r4.xlarge", 4, 30.5],
["r4.2xlarge", 8, 61],
["r4.4xlarge", 16, 122],
["r4.8xlarge", 32, 244],
["r4.16xlarge", 64, 488],
["x1.16xlarge", 64, 976],
["x1.32xlarge", 128, 1952],
["c5.large", 2, 4],
["c5.xlarge", 4, 8],
["c5.2xlarge", 8, 16],
["c5.4xlarge", 16, 32],
["c5.9xlarge", 36, 72],
["c5.12xlarge", 48, 96],
["c5.18xlarge", 72, 144],
["c5.24xlarge", 96, 192],
["c5a.large", 2, 4],
["c5a.xlarge", 4, 8],
["c5a.2xlarge", 8, 16],
["c5a.4xlarge", 16, 32],
["c5a.8xlarge", 32, 64],
["c5a.12xlarge", 48, 96],
["c5a.16xlarge", 64, 128],
["c5a.24xlarge", 96, 192],
["c4.large", 2, 3.75],
["c4.xlarge", 4, 7.5],
["c4.2xlarge", 8, 15],
["c4.4xlarge", 16, 30],
["c4.8xlarge", 36, 60],
["a1.medium", 1, 2],
["a1.large", 2, 4],
["a1.xlarge", 4, 8],
["a1.2xlarge", 8, 16],
["a1.4xlarge", 16, 32],
["t3.nano", 2, 0.5],
["t3.micro", 2, 1],
["t3.small", 2, 2],
["t3.medium", 2, 4],
["t3.large", 2, 8],
["t3.xlarge", 4, 16],
["t3.2xlarge", 8, 32],
["t3a.nano", 2, 0.5],
["t3a.micro", 2, 1],
["t3a.small", 2, 2],
["t3a.medium", 2, 4],
["t3a.large", 2, 8],
["t3a.xlarge", 4, 16],
["t3a.2xlarge", 8, 32],
["t2.nano", 1, 0.5],
["t2.micro", 1, 1],
["t2.small", 1, 2],
["t2.medium", 2, 4],
["t2.large", 2, 8],
["t2.xlarge", 4, 16],
["t2.2xlarge", 8, 32],
["m5.large", 2, 8],
["m5.xlarge", 4, 16],
["m5.2xlarge", 8, 32],
["m5.4xlarge", 16, 64],
["m5.8xlarge", 32, 128],
["m5.12xlarge", 48, 192],
["m5.16xlarge", 64, 256],
["m5.24xlarge", 96, 384],
["m4.large", 2, 8],
["m4.xlarge", 4, 16],
["m4.2xlarge", 8, 32],
["m4.4xlarge", 16, 64],
["m4.10xlarge", 40, 160],
["m4.16xlarge", 64, 256]
]
소스파일 > _writer.py (이슈 발생시)
/usr/local/lib/python3.10/dist-packages/openpyxl/cell/_writer.py 파일은 openpyxl 라이브러리의 일부로, Excel 시트에 있는 셀의 XML 표현을 작성하는 기능을 담당합니다.
openpyxl은 Python에서 Excel 파일을 읽고 쓰기 위한 라이브러리입니다. 이 코드를 수정할 수 있는 여러 가지 이유가 있습니다:
참조: /usr/local/lib/python3.10/dist-packages/openpyxl/cell/_writer.py
- 버그 수정:
openpyxl의 원래 코드에 버그가 있을 경우, 이를 수정하기 위해 코드를 변경할 수 있습니다. - 기능 추가: 기존 라이브러리에 원하는 기능이 없다면, 이 파일을 수정하여 원하는 기능을 추가할 수 있습니다.
- 퍼포먼스 향상:
openpyxl의 원래 코드보다 더 빠르게 실행되는 코드로 바꾸려는 시도를 할 수 있습니다. - 사용자 정의 동작: 특정 프로젝트나 애플리케이션의 요구 사항에 맞게 동작을 사용자 정의하기 위해 코드를 수정할 수 있습니다.
# Copyright (c) 2010-2023 openpyxl
from openpyxl.compat import safe_string
from openpyxl.xml.functions import Element, SubElement, whitespace, XML_NS, REL_NS
from openpyxl import LXML
from openpyxl.utils.datetime import to_excel, to_ISO8601
from datetime import timedelta
from openpyxl.worksheet.formula import DataTableFormula, ArrayFormula
from openpyxl.cell.rich_text import TextBlock
def _set_attributes(cell, styled=None):
"""
Set coordinate and datatype
"""
coordinate = cell.coordinate
attrs = {'r': coordinate}
if styled:
attrs['s'] = f"{cell.style_id}"
if cell.data_type == "s":
attrs['t'] = "inlineStr"
elif cell.data_type != 'f':
attrs['t'] = cell.data_type
value = cell._value
# if cell.data_type == "d":
# if hasattr(value, "tzinfo") and value.tzinfo is not None:
# raise TypeError("Excel does not support timezones in datetimes. "
# "The tzinfo in the datetime/time object must be set to None.")
if cell.data_type == "d":
if hasattr(value, "tzinfo") and value.tzinfo is not None:
value = value.replace(tzinfo=None)
if cell.parent.parent.iso_dates and not isinstance(value, timedelta):
value = to_ISO8601(value)
else:
attrs['t'] = "n"
value = to_excel(value, cell.parent.parent.epoch)
if cell.hyperlink:
cell.parent._hyperlinks.append(cell.hyperlink)
return value, attrs
def etree_write_cell(xf, worksheet, cell, styled=None):
value, attributes = _set_attributes(cell, styled)
el = Element("c", attributes)
if value is None or value == "":
xf.write(el)
return
if cell.data_type == 'f':
attrib = {}
if isinstance(value, ArrayFormula):
attrib = dict(value)
value = value.text
elif isinstance(value, DataTableFormula):
attrib = dict(value)
value = None
formula = SubElement(el, 'f', attrib)
if value is not None and not attrib.get('t') == "dataTable":
formula.text = value[1:]
value = None
if cell.data_type == 's':
inline_string = SubElement(el, 'is')
if isinstance(value, str):
text = SubElement(inline_string, 't')
text.text = value
whitespace(text)
else:
for r in value:
se = SubElement(inline_string, 'r')
if isinstance(r, TextBlock):
se2 = SubElement(se, 'rPr')
se2.append(r.font.to_tree())
text = r.name
else:
text = r
text = SubElement(se, 't')
text.text = text
whitespace(text)
else:
cell_content = SubElement(el, 'v')
if value is not None:
cell_content.text = safe_string(value)
xf.write(el)
def lxml_write_cell(xf, worksheet, cell, styled=False):
value, attributes = _set_attributes(cell, styled)
if value == '' or value is None:
with xf.element("c", attributes):
return
with xf.element('c', attributes):
if cell.data_type == 'f':
attrib = {}
if isinstance(value, ArrayFormula):
attrib = dict(value)
value = value.text
elif isinstance(value, DataTableFormula):
attrib = dict(value)
value = None
with xf.element('f', attrib):
if value is not None and not attrib.get('t') == "dataTable":
xf.write(value[1:])
value = None
if cell.data_type == 's':
with xf.element("is"):
if isinstance(value, str):
attrs = {}
if value != value.strip():
attrs["{%s}space" % XML_NS] = "preserve"
el = Element("t", attrs) # lxml can't handle xml-ns
el.text = value
xf.write(el)
#with xf.element("t", attrs):
#xf.write(value)
else:
for r in value:
with xf.element("r"):
if isinstance(r, TextBlock):
xf.write(r.font.to_tree(tagname='rPr'))
value = r.text
else:
value = r
attrs = {}
if value != value.strip():
attrs["{%s}space" % XML_NS] = "preserve"
el = Element("t", attrs) # lxml can't handle xml-ns
el.text = value
xf.write(el)
else:
with xf.element("v"):
if value is not None:
xf.write(safe_string(value))
if LXML:
write_cell = lxml_write_cell
else:
write_cell = etree_write_cell
[3] 결론
이를 통해 얻을 수 있는 기대효과와 장점은 아래와 같다.
- 통합 대시보드: 웹 인터페이스를 통해 AWS 리소스의 상태와 정보를 중앙화하여 한 눈에 볼 수 있게 됩니다. 여러 AWS 서비스의 정보를 조합하여 쉽게 파악할 수 있는 대시보드를 만들 수 있습니다.
- 사용자 편의성: 웹 인터페이스는 사용자 친화적이기 때문에, 기술적 지식이 없는 사용자도 AWS 리소스의 상태를 쉽게 확인할 수 있게 됩니다.
- 접근 제어: 웹 인터페이스를 통해 사용자별, 권한별로 리소스 정보에 대한 접근을 제어할 수 있습니다. 이를 통해 보안을 강화하고, 특정 정보의 접근을 제한할 수 있습니다.
- 보안 강화: SAML 기반의 SSO(Single Sign-On)를 통해 사용자 인증을 진행하면, 기존의 조직 내에서 사용하는 인증 시스템과 연동하여 일관된 보안 정책을 적용할 수 있습니다. 또한, 중복된 로그인 과정 없이 여러 시스템에 원활하게 접근할 수 있게 됩니다.
- 알림 및 모니터링: 웹 서비스를 통해 특정 리소스의 상태 변화나 임계값을 초과하는 경우 알림 기능을 구현할 수 있습니다. 이를 통해 문제 상황에 신속하게 대응할 수 있게 됩니다.
- 사용자 정의 리포트: 사용자의 요구 사항에 맞게 특정 리소스에 대한 리포트를 생성하고, 이를 웹 인터페이스를 통해 제공할 수 있습니다.
그렇다면 이러한 웹 서비스를 구현하기 위해 어떤 절차가 필요할까요?
- AWS SDK 및 API 활용: AWS 리소스의 정보를 가져오기 위해 AWS SDK(예: Boto3 for Python)나 AWS API를 활용합니다.
- 웹 서버 및 백엔드 구축: 웹 서버(예: Apache, Nginx)와 백엔드 프레임워크(예: PHP, Flask, Django)를 선택하여 개발환경을 구축합니다.
- SAML SSO 구현: AWS Cognito나 다른 SSO 솔루션을 활용하여 SAML 기반의 인증 시스템을 구현합니다.
- 프론트엔드 개발: 사용자의 요구 사항에 맞는 웹 인터페이스를 개발합니다. (예: React, Vue.js)
- 보안 및 최적화: 웹 서비스의 보안을 강화하고, 성능을 최적화합니다.
관리자가 철저한 보안을 통해서 직접적인 콘솔 접속을 지양하고, 더 효과적으로 자체 리소스를 안전하게 관리하고 모니터링할 수 있도록 개선을 하면 좋을 것 같습니다..